Introducing vCluster Auto Nodes — Practical deep dive

Sep 30, 2025
|
6
min Read

Kubernetes makes pods elastic, but nodes usually aren’t unless you bolt on cloud-specific autoscalers or keep expensive capacity idle. With vCluster Auto Nodes, each virtual cluster scales its own worker nodes on demand, anywhere: public cloud, private cloud, or bare metal. You get strict isolation (via Private Nodes) and true elasticity (via Karpenter), without tying your design to a single Cloud provider.
Private nodes is a new tenancy model that got introduced in vCluster version 0.27 where you can run vCluser as a hosted control plane on the host cluster and then join the nodes which will be private to that particular virtual cluster bringing in more isolation and the vcLuster auto nodes takes this to next level by integrating Karpenter and making the whole experience seamless. For a more deep dive on private nodes you can visit this blog.
Karpenter is a well respected open source tool that works really well for EKS but has limited support for other providers. With vCluster auto nodes, you get the power of Karpenter for any Kubernetes cluster be it on cloud or even bare metal. It is based on terraform and there is a terraform provider for almost everything.
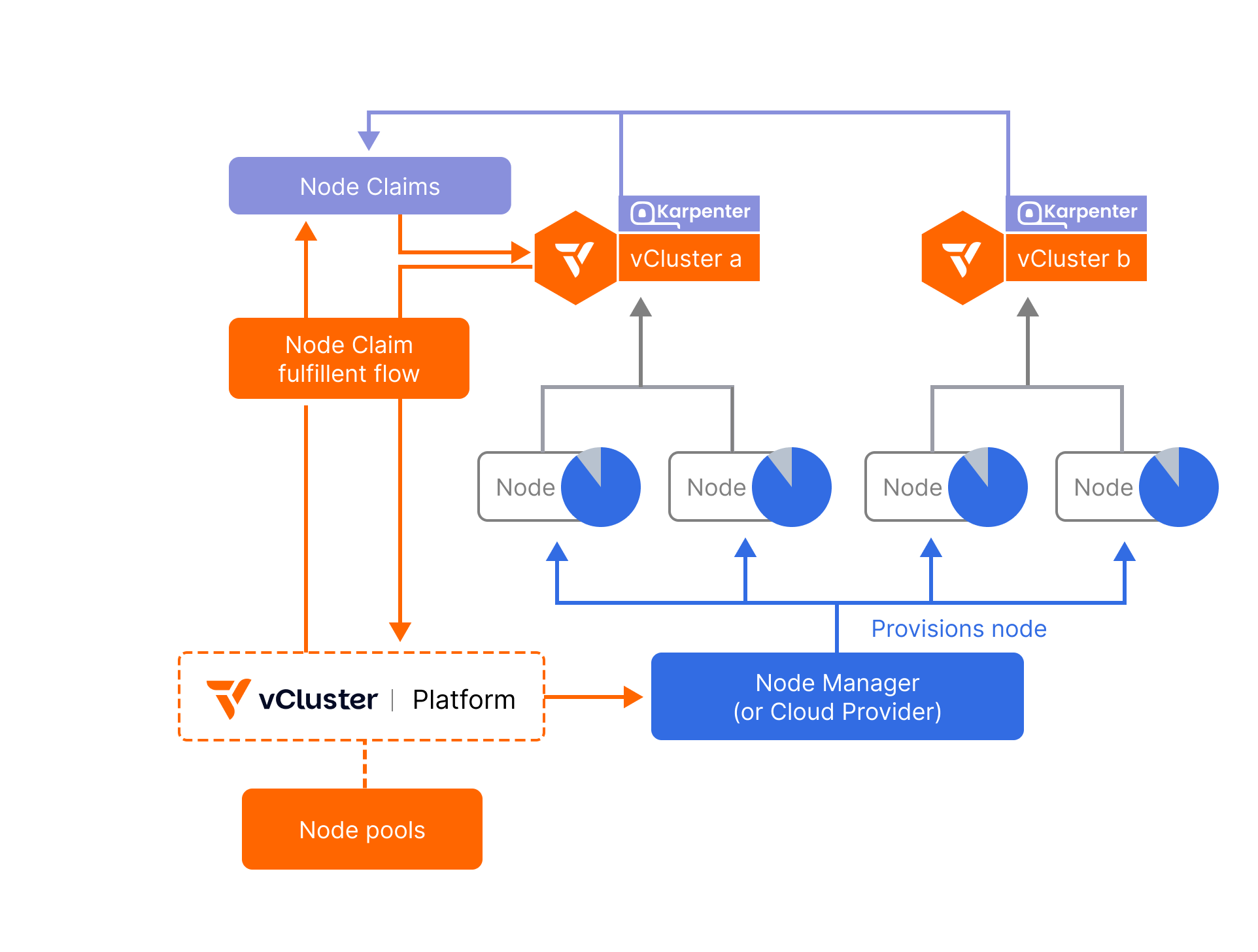
A request for capacity automatically created when pods in a vCluster are unschedulable. Karpenter inside the vCluster evaluates the pods’ resource requests and scheduling constraints (CPU, memory, GPU, labels/taints, topology) and generates a NodeClaim that specifies the type of node needed. The vCluster Platform then mirrors this into a platform-level NodeClaim and uses your configured node providers (e.g., Terraform, KubeVirt, NVIDIA BCM, cloud APIs) to provision and join the actual vCluster control plane running on the host Kubernetes cluster..
The component that fulfills Platform NodeClaims by actually provisioning machines. It can drive that using integrations like Terraform/OpenTofu, KubeVirt, or NVIDIA BCM. Its job is to create the VM/host, set up networking as needed, bootstrap via cloud-init/user-data, ensure the node registers with the vCluster control plane (for Private Nodes/Auto Nodes) with the right labels/taints, and later tear it down during disruption/scale-down when idle. Think of it as the executor that turns intent into real nodes.
The control plane for fulfillment. It receives NodeClaims from vClusters, applies your policies, limits, and requirements (e.g., allowed regions, instance families, GPU types), chooses the best node type (cost-aware), and asks the Node Manager to provision it. It also cleans up when nodes are no longer needed.
We’ll spin up a GKE cluster, install vCluster Platform, wire up Workload Identity for secure access to cloud resources, define a NodeProvider backed by Terraform on GCP, and create a vCluster whose privateNodes.autoNodes dynamically provision actual GCE VMs on demand. You’ll finish with a repeatable pattern to scale cluster capacity per vCluster, only when needed.
Flow:
privateNodes.autoNodes.enabled: true is created.Tip: Quotas are real: CPU (all regions) and PD-SSD GB. If you hit 403s, request more from the GCP console.
We’ll use saiyam-project and us-east1, based on your environment, adjust names as needed.
gcloud config set project saiyam-project
gcloud config set compute/region us-east1
gcloud config set compute/zone us-east1-bgcloud services enable \
container.googleapis.com \
compute.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com
Create a standard GKE cluster with Workload Identity:
gcloud container clusters create saiyam-autonodes \
--location=us-east1 \
--workload-pool=saiyam-project.svc.id.goog \
--machine-type=e2-standard-4 \
--num-nodes=3 \
--release-channel=regular \
--enable-ip-alias
Output:
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Creating cluster saiyam-autonodes in us-east1... Cluster is being health-checked (Kube
rnetes Control Plane is healthy)...done.
Created [https://container.googleapis.com/v1/projects/saiyam-project/zones/us-east1/clusters/saiyam-autonodes].
To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/us-east1/saiyam-autonodes?project=saiyam-project
kubeconfig entry generated for saiyam-autonodes.
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS
saiyam-autonodes us-east1 1.33.4-gke.1134000 34.74.194.21 e2-standard-4 1.33.4-gke.1134000 9 RUNNING
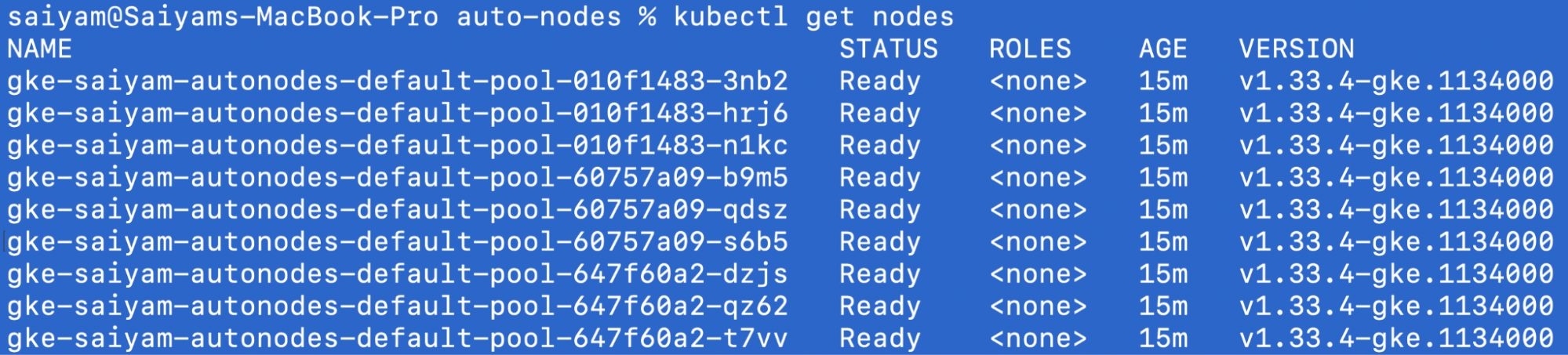
Verify nodes:
kubectl get nodes
Gotcha notes you hit:
--workload-pool=<CURRENT_PROJECT>.svc.id.goog.Add chart and install:
helm repo add loft https://charts.loft.sh
helm repo update
helm upgrade vcluster-platform vcluster-platform \
--install \
--repo https://charts.loft.sh/ \
--namespace vcluster-platform \
--create-namespace
Output:
Wait for pods:
kubectl get pods -n vcluster-platform
Output:

In order to login to the platform you can port forward the service and then login to the platform as for the auto nodes you need to get the platform logged in.
kubectl -n vcluster-platform port-forward svc/loft 9898:443
Forwarding from 127.0.0.1:9898 -> 10443
Forwarding from [::1]:9898 -> 10443
Now login to the platform via the UI first and then generate an Access Key and login via access key so that you can create the virtual cluster using the vCluster cli. You can also directly use the platform UI to create the vCluster.
vcluster platform login https://localhost:8888
23:28:34 info If the browser does not open automatically, please navigate to https://localhost:8888/login?cli=true
23:28:34 info If you have problems logging in, please navigate to https://localhost:8888/profile/access-keys, click on 'Create Access Key' and then login via 'vcluster platform login https://localhost:8888 --access-key ACCESS_KEY'
23:28:34 info Logging into vCluster Platform...
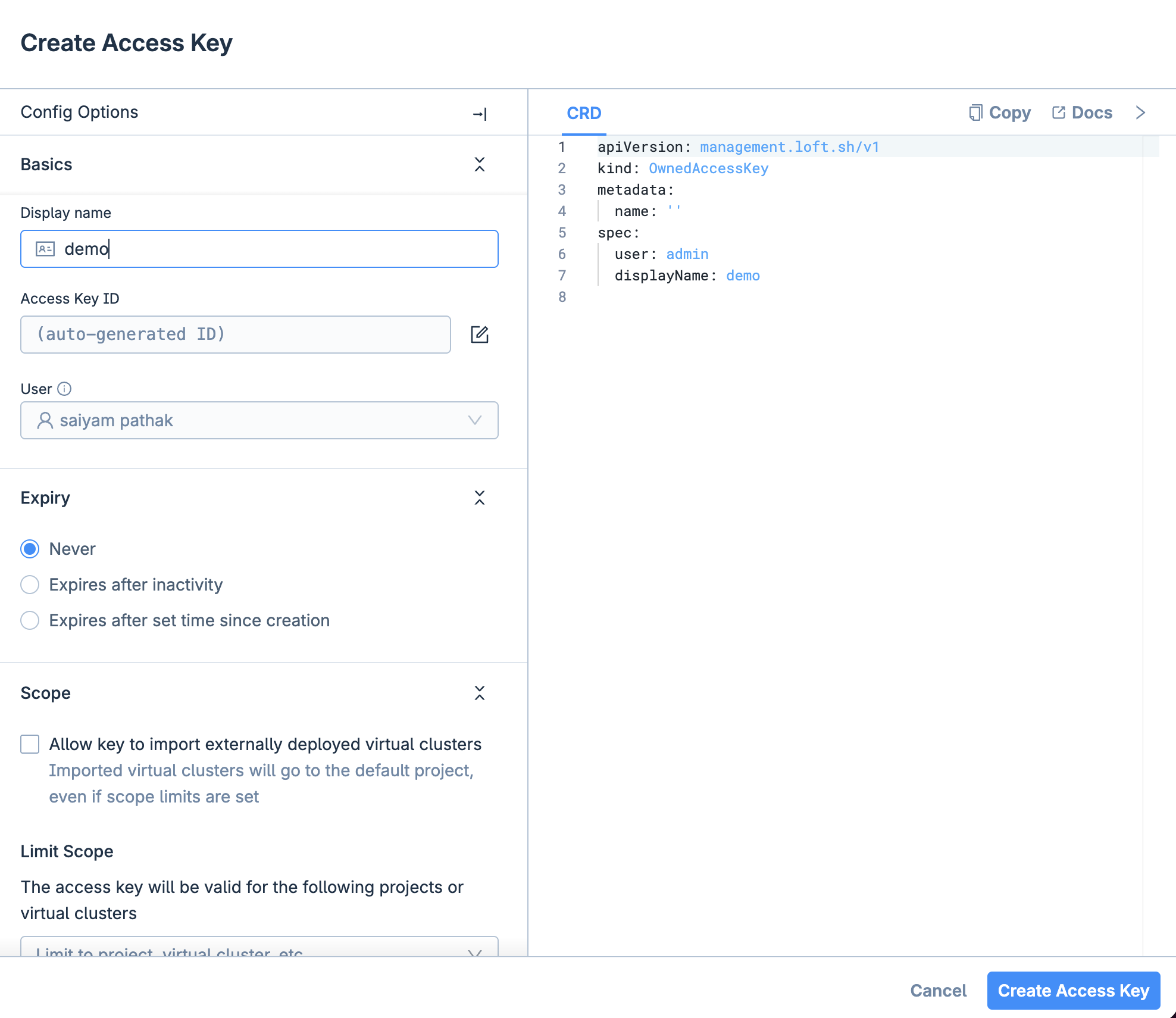
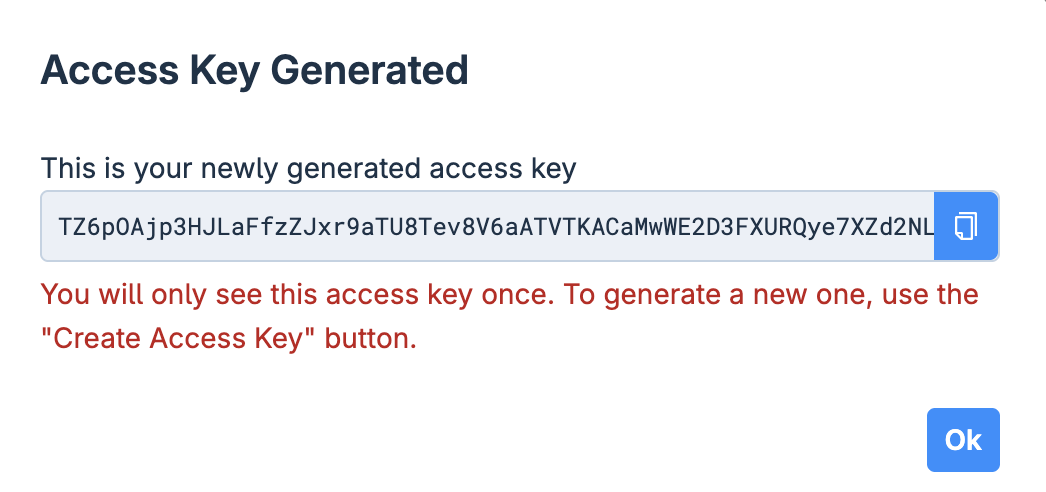
Now login using the Access Key

Workload Identity links a Kubernetes Service Account (KSA) to a Google Service Account (GSA) so pods can call Google APIs without JSON keys. In our case, the Platform controller (running as a KSA in vcluster-platform) needs cloud creds to fulfill Platform NodeClaims (e.g., create VMs, networks) via your Node Provider. Workload Identity gives you:
Set the variables in your terminal
PROJECT_ID=saiyam-project
LOCATION=us-east1
CLUSTER=saiyam-autonodes
PLAT_NS=vcluster-platform # namespace where Loft/vCluster Platform runs
KSA=loft # Kubernetes SA used by the Loft deployment
GSA_NAME=vcluster # Short name of the Google SA
GSA_EMAIL="${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud container clusters describe "$CLUSTER" \
--location "$LOCATION" \
--format="get(workloadIdentityConfig.workloadPool)"
Output:
saiyam-project.svc.id.goog
kubectl -n "$PLAT_NS" create serviceaccount "$KSA" \
--dry-run=client -o yaml | kubectl apply -f -
Output:
serviceaccount/vcluster created
gcloud iam service-accounts describe "$GSA_EMAIL" --format="value(email)" \
|| gcloud iam service-accounts create "$GSA_NAME" \
--display-name "vCluster Platform controller"
Output:
Created service account [vcluster].
gcloud iam service-accounts add-iam-policy-binding "$GSA_EMAIL" \
--role roles/iam.workloadIdentityUser \
--member "serviceAccount:${PROJECT_ID}.svc.id.goog[${PLAT_NS}/${KSA}]"
Output:
Updated IAM policy for serviceAccount [vcluster@saiyam-project.iam.gserviceaccount.com].
bindings:
- members:
- serviceAccount:saiyam-project.svc.id.goog[vcluster-platform/loft]
role: roles/iam.workloadIdentityUser
etag: BwY_Kf9nNZc=
version: 1
for role in roles/compute.admin roles/compute.networkAdmin roles/iam.serviceAccountUser; do
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="serviceAccount:${GSA_EMAIL}" \
--role="$role"
done
This is the exact role needed.
This references a sample repo with two templates:
environment – VPC/subnet/etc (per vCluster)node – actual VM definitionapiVersion: management.loft.sh/v1
kind: NodeProvider
metadata:
name: gcp-compute
spec:
terraform:
nodeEnvironmentTemplate:
git:
repository: https://github.com/loft-demos/beta-app.git
subPath: vcluster-use-cases/private-nodes/auto-nodes/gcp-terraform/environment
nodeTemplate:
git:
repository: https://github.com/loft-demos/beta-app.git
subPath: vcluster-use-cases/private-nodes/auto-nodes/gcp-terraform/node
nodeTypes:
- name: e2-standard-4-us-east1-b
resources:
cpu: "4"
memory: "16Gi"
properties:
project: "saiyam-project"
region: "us-east1"
zone: "us-east1-b"
instance-type: "e2-standard-4"
terraform.vcluster.com/credentials: "*"
- name: e2-standard-4-us-east1-c
resources:
cpu: "4"
memory: "16Gi"
properties:
project: "saiyam-project"
region: "us-east1"
zone: "us-east1-c"
instance-type: "e2-standard-4"
terraform.vcluster.com/credentials: "*"
- name: e2-standard-8-us-east1-b
resources:
cpu: "8"
memory: "32Gi"
properties:
project: "saiyam-project"
region: "us-east1"
zone: "us-east1-b"
instance-type: "e2-standard-8"
terraform.vcluster.com/credentials: "*"
- name: e2-standard-8-us-east1-c
resources:
cpu: "8"
memory: "32Gi"
properties:
project: "saiyam-project"
region: "us-east1"
zone: "us-east1-c"
instance-type: "e2-standard-8"
terraform.vcluster.com/credentials: "*"
Apply it:
kubectl apply -f node-provider.yamlnodeprovider.management.loft.sh/gcp-compute created
Output:
kubectl get nodeproviders.storage.loft.sh gcp-compute -o yaml
apiVersion: storage.loft.sh/v1
kind: NodeProvider
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"storage.loft.sh/v1","kind":"NodeProvider","metadata":{"annotations":{},"name":"gcp-compute"},"spec":{"terraform":{"nodeTemplate":{"git":{"repository":"https://github.com/loft-sh/terraform-gcp-compute-node.git"}},"nodeTypes":[{"name":"e2-standard-4-us-east1-b","properties":{"instance-type":"e2-standard-4","topology.kubernetes.io/zone":"us-east1-b"},"resources":{"cpu":"4","memory":"16Gi"}},{"name":"e2-standard-8-us-east1-c","properties":{"instance-type":"e2-standard-8","topology.kubernetes.io/zone":"us-east1-c"},"resources":{"cpu":"8","memory":"32Gi"}}]}}}
creationTimestamp: "2025-09-19T11:08:50Z"
finalizers:
- loft.sh/cleanup
generation: 3
name: gcp-compute
resourceVersion: "1758280130547183008"
uid: 1d3a4cee-7479-40ef-ac12-307653c05a2b
spec:
terraform:
nodeTemplate:
git:
repository: https://github.com/loft-sh/terraform-gcp-compute-node.git
nodeTypes:
- metadata: {}
name: e2-standard-4-us-east1-b
properties:
instance-type: e2-standard-4
terraform.vcluster.com/credentials: '*'
topology.kubernetes.io/zone: us-east1-b
resources:
cpu: "4"
memory: 16Gi
- metadata: {}
name: e2-standard-8-us-east1-c
properties:
instance-type: e2-standard-8
terraform.vcluster.com/credentials: '*'
topology.kubernetes.io/zone: us-east1-c
resources:
cpu: "8"
memory: 32Gi
status:
conditions:
- lastTransitionTime: "2025-09-19T11:08:50Z"
status: "True"
type: Ready
- lastTransitionTime: "2025-09-19T11:08:50Z"
status: "True"
type: Initialized
phase: Available
You should see status.phase: Available
We’ll expose the control plane via LoadBalancer and enable auto nodes with constraints (project/region/zone/instance-type) and a capacity cap.
controlPlane:
service:
spec:
type: LoadBalancer
privateNodes:
enabled: true
autoNodes:
dynamic:
- name: gcp-cpu-nodes
provider: gcp-compute
# Requirements MUST match the NodeProvider nodeTypes' property KEYS + VALUES
requirements:
- property: project
operator: In
values: ["saiyam-project"]
- property: region
operator: In
values: ["us-east1"]
- property: zone
operator: In
values: ["us-east1-b","us-east1-c"]
- property: instance-type
operator: In
values: ["e2-standard-4","e2-standard-8"]
limits:
# keep these comfortably above your expected size
nodes: "6"
cpu: "64"
memory: "128Gi"
Create a vCluster via platform (so the --project flag applies):
vcluster create vcluster-demo \
--namespace vcluster-demo \
--values vcluster.yaml \
--driver platform \
--connect=false
Output:
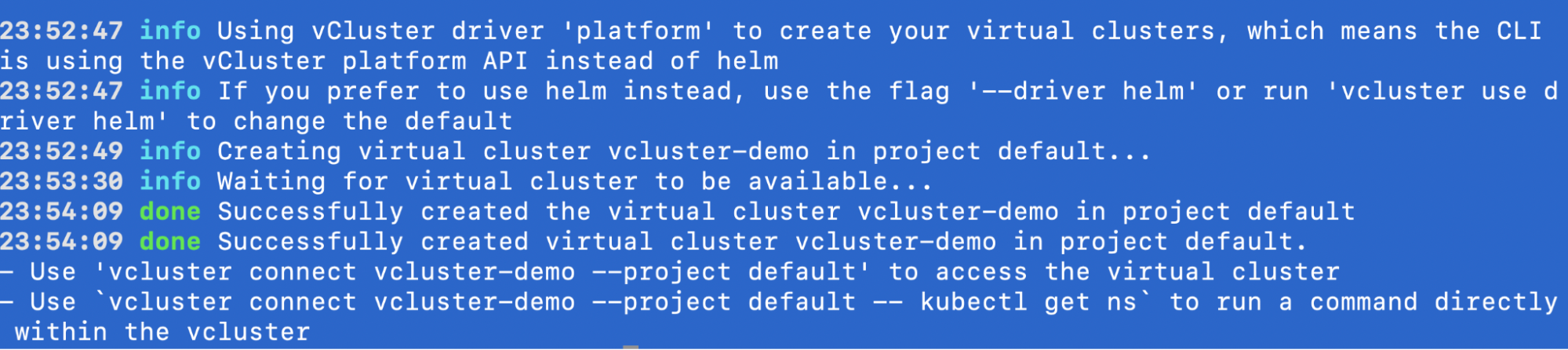
When the vCluster schedules capacity, the platform will create NodeClaims which your provider will reconcile:
kubectl get nodeclaims.storage.loft.sh -A
kubectl -n p-default get events | grep -i nodeclaim
You will see something liek this in the vcluster logs
{"name":"gcp-cpu-nodes"}, "NodeClaim": {"name":"gcp-cpu-nodes-8cr2k"}, "requests": {"cpu":"120m","memory":"114Mi","pods":"5"}, "instance-types": "gcp-compute.e2-standard-4-us-east1, gcp-compute.e2-standard-8-us-east1"}
2025-09-23 18:33:00 INFO karpenter cloudprovider/cloudprovider.go:84 Creating node claim {"component": "vcluster", "controller": "nodeclaim.lifecycle", "controllerGroup": "karpenter.sh", "controllerKind": "NodeClaim", "NodeClaim": {"name":"gcp-cpu-nodes-8cr2k"}, "namespace": "", "name": "gcp-cpu-nodes-8cr2k", "reconcileID": "225b9b47-5952-4b7b-86cb-d259c1b4258d", "nodeClaim": "gcp-cpu-nodes-8cr2k"}
2025-09-23 18:33:00 INFO karpenter cloudprovider/cloudprovider.go:120 Waiting for node claim to be provisioned... {"component": "vcluster", "controller": "nodeclaim.lifecycle", "controllerGroup": "karpenter.sh", "controllerKind": "NodeClaim", "NodeClaim": {"name":"gcp-cpu-nodes-8cr2k"}, "namespace": "", "name": "gcp-cpu-nodes-8cr2k", "reconcileID": "225b9b47-5952-4b7b-86cb-d259c1b4258d", "nodeClaim": "vcluster-demo-hxfjb"}

You will see a node appearing in the Google Cloud Console

kubectl -n p-default get nodeclaims.management.loft.shNAME STATUS VCLUSTER TYPE CREATED AT
vcluster-demo-hxfjb Available vcluster-demo gcp-compute.e2-standard-4-us-east1 2025-09-23T19:04:30Z
You can also observe the flow as in the diagram below:
And confirm new nodes joining the host:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
gcp-vcluster-demo-beta-c8ae3426-001 Ready <none> 117s v1.33.4
Auto Nodes gives each vCluster just-in-time physical capacity, without pre-allocating, large, or static node pools. Based on Karpenter, a cluster autoscaler for Kubernetes, vCluster with Auto Nodes now chooses the best node for the requested amount of pods and resources required for node management and scheduling. Let us know your thoughts on Karpenter for any Kubernetes cluster and join our slack to join the conversation.
Deploy your first virtual cluster today.
