What are Virtual Kubernetes Clusters?
Virtual clusters are fully working Kubernetes clusters that run on top of other Kubernetes clusters. Compared to fully separate "real" clusters, virtual clusters reuse worker nodes and networking of the host cluster. They have their own control plane and schedule all workloads into a single namespace of the host cluster. Like virtual machines, virtual clusters partition a single physical cluster into multiple separate ones.

The virtual cluster itself only consists of the core Kubernetes components: API server, controller manager, storage backend (such as etcd, sqlite, mysql etc.) and optionally a scheduler. To reduce virtual cluster overhead, vCluster builds by default on k3s, which is a fully working, certified, lightweight Kubernetes distribution that compiles the Kubernetes components into a single binary and disables by default all unneeded Kubernetes features, such as the pod scheduler or certain controllers.
Besides k3s, other Kubernetes distributions such as k0s and vanilla k8s are supported. In addition to the control plane, there is also a Kubernetes hypervisor that emulates networking and worker nodes inside the virtual cluster. This component syncs a handful of core resources that are essential for cluster functionality between the virtual and host cluster:
- Pods: All pods that are started in the virtual cluster are rewritten and then started in the namespace of the virtual cluster in the host cluster. Service account tokens, environment variables, DNS and other configurations are exchanged to point to the virtual cluster instead of the host cluster. Within the pod, so it seems that the pod is started within the virtual cluster instead of the host cluster.
- Services: All services and endpoints are rewritten and created in the namespace of the virtual cluster in the host cluster. The virtual and host cluster share the same service cluster IPs. This also means that a service in the host cluster can be reached from within the virtual cluster without any performance penalties.
- PersistentVolumeClaims: If persistent volume claims are created in the virtual cluster, they will be mutated and created in the namespace of the virtual cluster in the host cluster. If they are bound in the host cluster, the corresponding persistent volume information will be synced back to the virtual cluster.
- Configmaps & Secrets: ConfigMaps or secrets in the virtual cluster that are mounted to pods will be synced to the host cluster, all other configmaps or secrets will purely stay in the virtual cluster.
- Other Resources: Deployments, statefulsets, CRDs, service accounts etc. are NOT synced to the host cluster and purely exist in the virtual cluster.
See synced resources for more information about what resources are synced.
In addition to the synchronization of virtual and host cluster resources, the hypervisor proxies certain Kubernetes API requests to the host cluster, such as pod port forwarding or container command execution. It essentially acts as a reverse proxy for the virtual cluster.
Why use Virtual Kubernetes Clusters?
Virtual clusters can be used to partition a single physical cluster into multiple clusters while leveraging the benefits of Kubernetes, such as optimal resource distribution and workload management. While Kubernetes already provides namespaces for multiple environments, they are limited in terms of cluster-scoped resources and control-plane usage:
Cluster-Scoped Resources: Certain resources live globally in the cluster, and you can’t isolate them using namespaces. For example, installing different versions of an operator at the same time is not possible within a single cluster.
Shared Kubernetes Control Plane: The API server, etcd, scheduler, and controller-manager are shared in a single Kubernetes cluster across all namespaces. Request or storage rate-limiting based on a namespace is very hard to enforce and faulty configuration might bring down the whole cluster.
Virtual clusters also provide more stability than namespaces in many situations. The virtual cluster creates its own Kubernetes resource objects, which are stored in its own data store. The host cluster has no knowledge of these resources.
Isolation like this is excellent for resiliency. Engineers who use namespace-based isolation often still need access to cluster-scoped resources like cluster roles, shared CRDs or persistent volumes. If an engineer breaks something in one of these shared resources, it will likely fail for all the teams that rely on it.
Because you can have many virtual clusters within a single cluster, they are much cheaper than the traditional Kubernetes clusters, and they require lower management and maintenance efforts. This makes them ideal for running experiments, continuous integration, and setting up sandbox environments.
Finally, virtual clusters can be configured independently of the physical cluster. This is great for multi-tenancy, like giving your customers the ability to spin up a new environment or quickly setting up demo applications for your sales team.
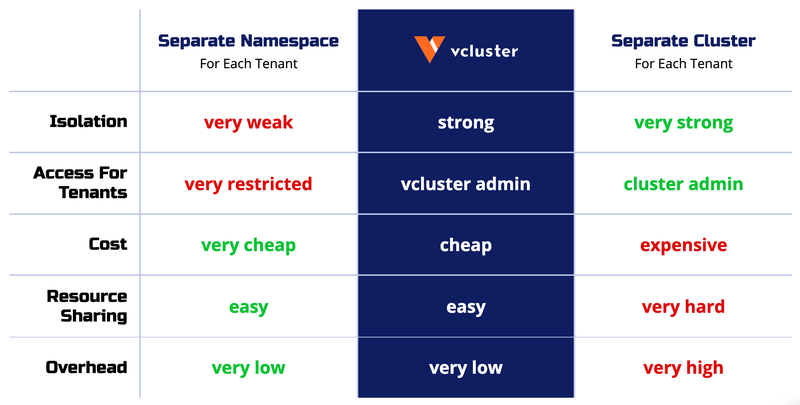
Benefits of vClusters
vClusters provide immense benefits for large-scale Kubernetes deployments and multi-tenancy.
- Full Admin Access:
- Deploy operators with CRDs, create namespaces and other cluster-scoped resources that you normally can't create inside a namespace.
- Taint and label nodes without influencing the host cluster. See Nodes and Pod Scheduling for more information.
- Reuse and share services across multiple virtual clusters with ease.
- Cost Savings:
- Create lightweight vClusters that share the underlying host cluster instead of creating separate "real" clusters.
- Auto-scale, purge, snapshot, and move your vClusters, since they are Kubernetes deployments.
- Low Overhead:
- vClusters are super lightweight and only reside in a single namespace.
- vClusters run with K3s, a super low-footprint K8s distribution. You can use other supported distributions such as K0s or vanilla Kubernetes. AWS EKS is a supported distribution that is now deprecated.
- The vCluster control plane runs inside a single pod. Open source vCluster also uses a CoreDNS pod for vCluster-internal DNS capabilities. With vCluster.Pro, however, you can enable the integrated CoreDNS so you don't need the additional pod.
- No Network Degradation:
- Since the pods and services inside a vCluster are actually being synchronized down to the host cluster, they are effectively using the underlying cluster's pod and service networking. The vCluster pods are as fast as other pods in the underlying host cluster.
- API Server Compatibility:
- vClusters run with the API server from the Kubernetes distribution that you choose to use. This ensures 100% Kubernetes API server compliance.
- vCluster manages its API server, controller-manager, and a separate, isolated data store. Use the embedded SQLite or a full-blown etcd if that's what you need. See Persisting vCluster data for a list of supported data stores.
- Security:
- vCluster users need fewer permissions in the underlying host cluster / host namespace.
- vCluster users can manage their own CRDs independently and can even modify RBAC inside their own vClusters.
- vClusters provide an extra layer of isolation. Each vCluster manages its own API server and control plane, which means that fewer requests to the underlying cluster need to be secured.
- Scalability:
- Less pressure / fewer requests on the K8s API server in a large-scale cluster.
- Higher scalability of clusters via cluster sharding / API server sharding into smaller vClusters.
- No need for cluster admins to worry about conflicting CRDs or CRD versions with a growing number of users and deployments.