Enterprise AI Factory
Give every team in your organization a production-grade AI environment without the overhead of managing separate clusters. Production ML teams get private GPU nodes and full isolation. Dev and experiment teams share a node pool and provision on demand. Platform keeps everything governed, audited, and within budget.
Typical stack: Platform on an existing cloud Kubernetes cluster or Standalone on-premises. Private nodes for production ML teams. Shared node pool for dev and experiment workloads. vMetal optional for on-premises GPU fleets.
Shared nodes are a supported, common model for trusted tenants. They give each tenant control-plane, API, and namespace isolation, but tenant workloads share the same kernel and physical nodes. They aren't a security boundary for untrusted tenants with Kubernetes access or arbitrary workload execution. Good fits are development, testing, CI/CD, and internal engineering teams.
Use private nodes for external, resale, regulated, or otherwise untrusted tenant offerings, optionally with vNode for runtime isolation.
NetworkPolicy is an added isolation layer worth enabling even for trusted tenants. vCluster can create the policies for you through policies.networkPolicy, and your control plane cluster's CNI enforces them. Confirm your CNI supports enforcement, since some accept NetworkPolicy resources without acting on them. See the security baseline.
This path serves your organization's own teams. The shared node tier is for internal dev and experiment workloads only. If you serve external customers or resell access, use the AI Cloud path, which gives each customer private nodes.
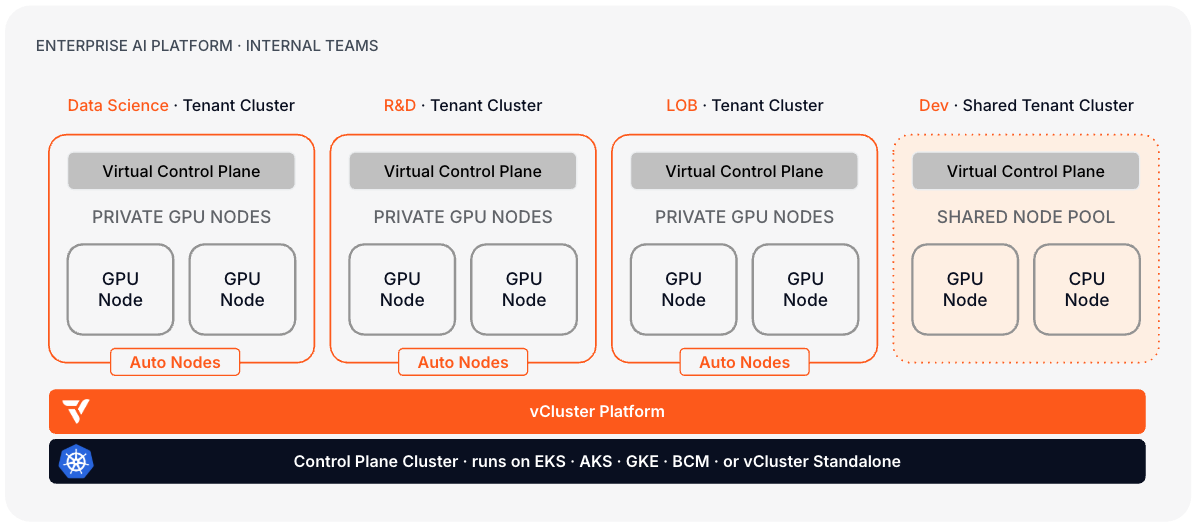
What makes this path different: Your teams use Platform directly, or through an internal portal built on top of it. Self-service provisioning, standardized GPU environments, and chargeback visibility are what you are building toward.
Day 0: Design decisions
| Decision | Read next | Outcome |
|---|---|---|
| Decide the Control Plane Cluster foundation | Architecture, Deployment basics | Run the Control Plane Cluster on an existing managed Kubernetes service (EKS, AKS, GKE) or vCluster Standalone on on-premises servers. |
| Define team tenancy tiers | Private Nodes, Deployment basics | Classify teams: production AI workloads on private GPU nodes, dev and experiment on shared nodes. |
| Define project and quota structure | Projects, Quotas | Map projects to teams or business units. Set GPU, CPU, and memory quotas per project. |
| Plan GPU tooling and AI stacks | Certified Stacks | Standardize GPU Operator, scheduler (Run.ai, Kueue, Volcano), and developer environment (Jupyter, VS Code) across teams using Certified Stacks. |
| Choose the runtime isolation model | vNode docs | vNode is recommended when teams run agentic workloads, untrusted code execution, or need root access inside containers without the risk of node escape. |
| Plan SSO and governance | SSO, RBAC | Integrate with your corporate identity provider. Define which teams can self-service create clusters and which require approval. |
Day 1: Stand up the first production environment
- Install vCluster Platform on your Control Plane Cluster.
- Configure SSO, teams, and permissions against your corporate identity provider.
- Create projects, templates, and quotas per team or business unit.
- Configure the shared node pool: pod security standard, network policy, and resource quota.
- Configure private GPU nodes for production teams: join nodes manually or configure Auto Nodes.
- Set up vMetal if on-premises GPU servers are part of the fleet.
- Deploy Certified Stacks as the baseline template for GPU-enabled tenant clusters.
- Install vNode on nodes designated for agentic or privileged workloads.
- Provision the first tenant cluster for each tier (shared and private) and validate GPU access, quota enforcement, and network isolation. For shared tiers, confirm the control plane cluster's CNI enforces NetworkPolicy. With
sync.toHost.networkPoliciesenabled, apply a default-deny policy and confirm the blocked connection is refused. See the security baseline. - Document how teams request clusters, retrieve kubeconfigs, request quota increases, and report issues.
Day 2: Operate
| Operation | Read next |
|---|---|
| Monitor platform and team workloads | Fleet monitoring, monitoring overview |
| Manage private node capacity | Auto Nodes, manage private nodes |
| Upgrade clusters and Platform | Upgrade vCluster, upgrade Platform |
| Back up and restore | Snapshots, Platform backup |